codegraph: exact code search for a coding agent
TL;DR
- Coding agents search code with grep and embeddings. For structural questions (who implements this interface, who calls this, what breaks if I change this signature) they guess, and they miss things.
- The Go compiler already knows those answers exactly. codegraph pulls them out of the type checker and stores them as a graph: nodes are types, functions and fields; edges are calls, implements, returns and params.
- A coding agent then runs exact graph queries instead of fuzzy text search. On etcd (roughly 245,000 lines of Go) it found every implementation of an interface where the text-based agents found a fraction.
- It was also more than ten times faster on some queries and used a fraction of the tokens, because the structure comes from a query, not from the model reading files.
Coding agents are good at writing code and surprisingly bad at finding it. codegraph fixes the finding part by handing the agent the map the compiler already builds.
The problem
Ask a coding agent a structural question about a large codebase. Who implements this interface? Who calls this method? What breaks if I change this function's signature? Under the hood it does what you would do: it greps for names and reads the files that come back, maybe re-ranked by an embedding search.
That works for finding a string. It does not work for finding a relationship. A type can implement an interface without ever naming it. A method can be called through an interface value, so the call site never mentions the concrete type. Grep sees text. Embeddings see things that look similar. Neither sees the type graph, which is the thing the question is actually about.
For a refactor this is the difference between safe and broken. If the agent finds six of the twelve implementations of an interface and then changes the interface, the build breaks in the six it missed.
The idea
The compiler already answers all of these. To type-check the code it has to resolve every call to the exact function it binds to, and work out which concrete types satisfy which interfaces. That information exists for a moment during the build and is then thrown away.
codegraph keeps it. It runs the Go type checker over a repository, reads the resolved relationships off it, and stores them as a graph. Nodes are the things in the code: packages, types, interfaces, struct fields, functions, variables. Edges are how they relate: CALLS, IMPLEMENTS, RETURNS, PARAMS, IMPORTS. This shape has a name, a code property graph. Once it is a graph, "who implements this interface" is one hop, not a search.
Extracting the graph
I load each package with full type information, not just the syntax:
cfg := &packages.Config{
Mode: packages.NeedTypes | packages.NeedTypesInfo | packages.NeedSyntax |
packages.NeedDeps | packages.NeedImports | packages.NeedName,
Dir: dir,
Tests: true,
}
pkgs, err := packages.Load(cfg, pattern)NeedTypes and NeedTypesInfo are the important ones. They make the loader run the type checker and hand back the resolved type for every identifier. With that in hand, extraction is a set of AST walks that read relationships off the type info instead of guessing them from names.
Calls
A call like obj.Method() is just text in the syntax tree. The type checker knows exactly which Method it is. I look the call up in the resolved type info and qualify it by its receiver type, so two methods with the same name on different types stay separate:
// obj.Method() is just text in the AST; the type checker knows the real target
obj := info.Uses[sel.Sel]
if fn, ok := obj.(*types.Func); ok {
if recv := fn.Type().(*types.Signature).Recv(); recv != nil {
// a method: qualify by receiver type so same-named methods stay distinct
callee := pkgPath + "." + recvTypeName + "." + fn.Name()
calls = append(calls, callee)
}
}Implements
Implements is the edge text search can never get right, so it is the one worth doing properly. Go has the analysis built in: the satisfy package is what the standard refactoring tools use to check assignability. I run it over each package and record an edge for every concrete type that satisfies an interface:
fi := satisfy.Finder{Result: make(map[satisfy.Constraint]bool)}
fi.Find(pkg.TypesInfo, pkg.Syntax)
for c := range fi.Result {
// c.RHS satisfies the interface c.LHS: record an IMPLEMENTS edge
implements[c.RHS.String()] = append(implements[c.RHS.String()], c.LHS.String())
}This is exact. It finds the types that satisfy an interface structurally, whether or not they ever mention it by name, which is precisely the set grep cannot find.
The graph
Run that over a whole repository, one module at a time, and you get a graph. Here is etcd, roughly 245,000 lines of Go, with every node and edge loaded into the database:
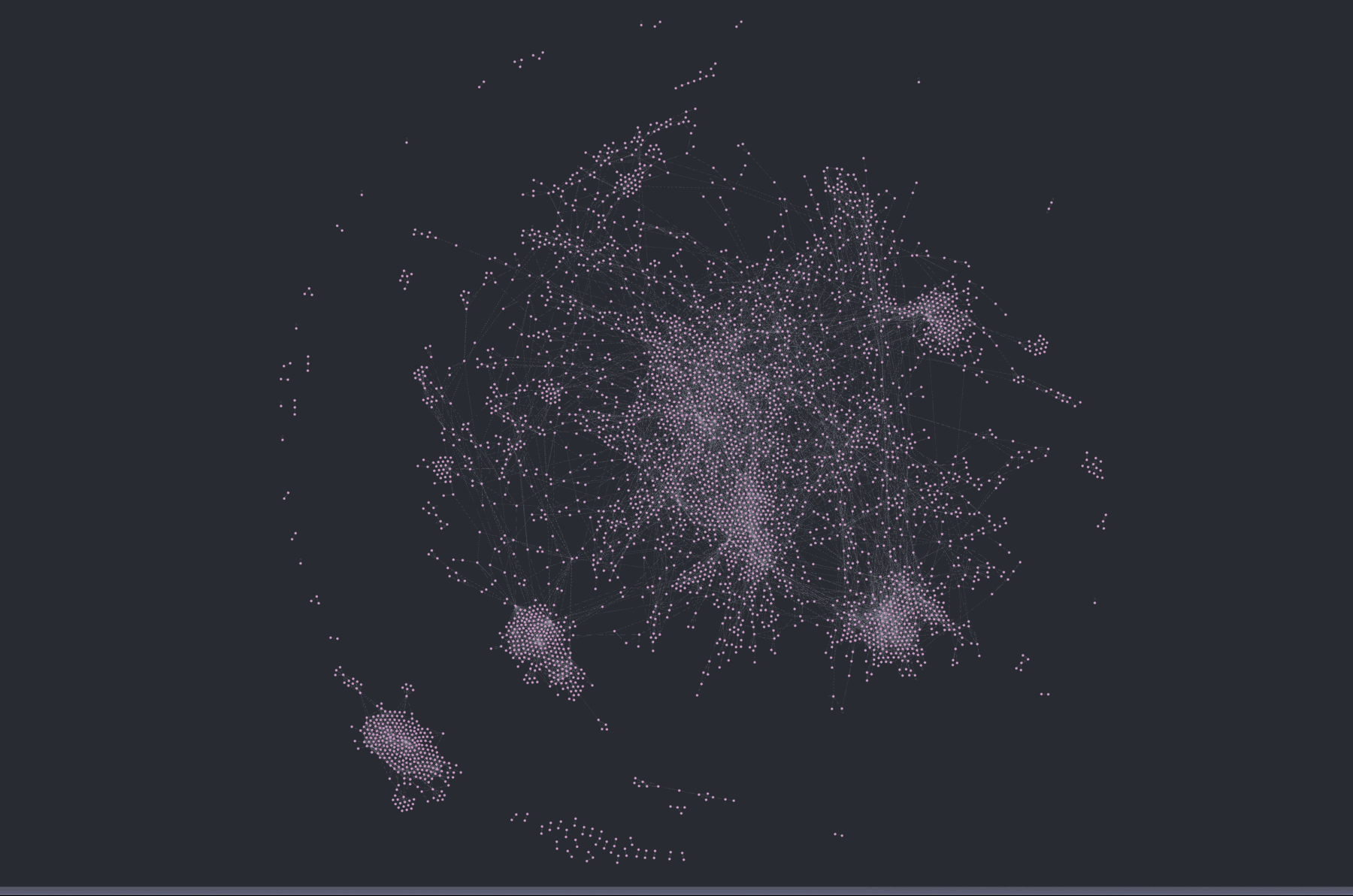
etcd as a code graph. Every dot is a symbol, every line a resolved relationship. The dense clusters are the packages with the most internal structure.
Loading is two passes: write all the nodes first, then all the edges, so an edge never points at a node that is not there yet.
Giving it to the agent
On top of the graph sits a small CLI coding agent. It is an ordinary function-calling loop over an LLM, with the graph exposed as tools:
search_code_symbols: find a symbol by name, qualified name, or kind.get_symbol_details: pull a symbol's code, docs, and its edges (what it calls, implements, returns, and takes as parameters).grep_code_nodes: a text search, but over the graph's nodes, for the genuinely fuzzy questions.
Plus the usual file tools: read a file, read a line range, list a directory, apply a patch.
The model decides which to use. For a relationship question it runs a graph query and gets the exact answer back in one hop. For a vague one it greps. The point is that the structural questions, the ones it used to guess at, now have a tool that does not guess.
Did it work
I tested it against text-based agents on etcd. Same questions, same repo.
- Who implements the client
KVinterface? The graph returned all twelve implementations. The two text-based agents I compared against returned six and zero. - Who uses the
Stringmethod on the v3 client types? The graph answered in 19 seconds. The agent doing it by reading files took over four minutes. - A deliberately misspelled query ("which interface does fake bas kv implemeent") resolved through fuzzy search in 3 seconds and about 1,300 tokens, against 12 seconds and about 13,000 tokens for the read-the-files approach.
The token numbers are the quiet win. When the structure comes from a query, the model does not have to read a pile of files into its context to reconstruct it, so the same answer costs a fraction of the tokens.
Where it goes
Two directions I think are worth it:
- Embeddings on the nodes. The graph is exact but literal. Add a vector index over each node's code and you can ask a fuzzy question and a structural one in the same query: find code that looks like X and is called by Y. The database supports it. I had the index defined and not yet wired in.
- More languages. The extractor is one interface behind a language-agnostic graph schema. Go is the first because its type checker is so good to work with. The same shape works for any typed language with a real compiler front end.
The core idea is small and I think it is right: a coding agent should not guess at things the compiler already knows. The graph is just a way to hand it those answers.